Oskar Hahn (Sep 11 2024 at 07:38): Oskar Hahn (Sep 11 2024 at 07:38):
Oskar Hahn (Sep 11 2024 at 07:38): Oskar Hahn (Sep 11 2024 at 07:38):I heard about tiger style and I think I learned a lot from reading it. But there is one point in it, that was surprising for me. In this talk Joran Greef says, they run all there assertions in productions. Before hearing this, it was clear to me, that assertions are a thing for the debug build, and are disabled in production. But maybe he is right. The values, that you assert are probably in a CPU-Cache anyway, so it is probably fast to compare them.
I would like to hear your opinion on this.
I know, that roc only runs inline exceptions in dev builds. I also remember, that there where discussions to change this. But I could not find them and I don't remember, what the result was.
Brendan Hansknecht (Sep 11 2024 at 15:31):I think we should have a flag to support this
Richard Feldman (Sep 11 2024 at 16:23):I think crash is the right way to support this
Richard Feldman (Sep 11 2024 at 16:23):crash essentially has the same semantics as an assertion
Richard Feldman (Sep 11 2024 at 16:26):sure, or write the conditional inline :big_smile:
Oskar Hahn (Sep 11 2024 at 16:40):You mean something like:
assert : Bool -> {}
assert = \condition
if condition then
{}
else
crash "assertion failed"
I think
crashis the right way to support this
I disagree. Being able to promote expects to be caught in production is way more useful.
Brendan Hansknecht (Sep 11 2024 at 19:25):This is something exceptionally useful to be configured at compile time.
Brendan Hansknecht (Sep 11 2024 at 19:25):For example, I have seen setups where a few servers run with the equivalent of expect on in production in order to be canaries that can help catch bugs, but overall avoid slowing down all requests with expects.
Brendan Hansknecht (Sep 11 2024 at 19:27):I think it is most useful if expects can be configured on by package, but even having it globally is really useful.
Richard Feldman (Sep 11 2024 at 19:27):Brendan Hansknecht said:
Being able to promote expects to be caught in production is way more useful.
to me, promoting expects to be caught in production makes them basically useless :big_smile:
Richard Feldman (Sep 11 2024 at 19:27):the whole point of the feature is to have the peace of mind that it won't be run in production
Richard Feldman (Sep 11 2024 at 19:27):but as soon as it can be, I need to think about performance and graceful error recovery again
Richard Feldman (Sep 11 2024 at 19:28):like either it can be run in production, in which case I have to think about those things (because I care about production), or it can't be, in which case I am free to not think about those things
Richard Feldman (Sep 11 2024 at 19:29):so allowing it to be isn't an enhancement of the feature, it's eliminating what I consider the primary benefit of the feature - namely, being able to write whatever checks feel most useful without regard for performance or graceful error recovery because I know for sure they will never be run in production! :smiley:
Brendan Hansknecht (Sep 11 2024 at 19:29):I think this is much more a user preference. Which is why I think it should only be opt in
Richard Feldman (Sep 11 2024 at 19:30):for example, I use debug_assert! liberally in Rust because I know it won't affect runtime perf
Richard Feldman (Sep 11 2024 at 19:30):if there were a way for us to situationally make debug_assert!s run in prod builds, then I would probably never use it
Richard Feldman (Sep 11 2024 at 19:30):certainly not in library code
Brendan Hansknecht (Sep 11 2024 at 19:30):The most obvious reason for me to want expect in production is that sometimes dev builds are too slow to ever be worth running. So I want to run tests with all the extra asserts, but I want to run production builds for performance and runtime reasons
Brendan Hansknecht (Sep 11 2024 at 19:31):In rust, I would do this with -C debug-assertions
Richard Feldman (Sep 11 2024 at 19:31):ohh wait, so do you mean running a "production build" locally but not actually shipping it?
Sam Mohr (Sep 11 2024 at 19:32):Well, it sounds like that's another argument as to why we want two orthogonal args for running roc code: --optimize=none,speed,size for performance, and --deploy-env=dev,prod for deployment environment
Richard Feldman (Sep 11 2024 at 19:32):yeah we've talked about a --release before as distinct from --optimize and that totally makes sense to me in this situation
Richard Feldman (Sep 11 2024 at 19:32):like expects are removed in --release but not necessarily --optimize
Sam Mohr (Sep 11 2024 at 19:32):Where --deploy-env=prod always disables expects, irrespective
Sam Mohr (Sep 11 2024 at 19:34):The --release flag should probably be added to this Roc CLI workflow issue: https://github.com/roc-lang/roc/issues/6637
Brendan Hansknecht (Sep 11 2024 at 19:34):I need 3 configs in my mind:
Richard Feldman (Sep 11 2024 at 19:35):always in production for some very hardened services
I just don't understand why it would be desirable to use expect for this instead of e.g. crash :sweat_smile:
Richard Feldman (Sep 11 2024 at 19:35):like if you want it to always crash on the error, why not use the language feature that's for that?
Kilian Vounckx (Sep 11 2024 at 19:36):Brendan Hansknecht said:
I need 3 configs in my mind:
- optimized code, no expects
- optimized code with expects (could be used for testing, fuzzing, a canary in production, or always in production for some very hardened services like tigerbeetle)
- debug with expects
I think zig has roughly these 3 no?
And ReleaseSmall of course, but that is another topic entirely
Brendan Hansknecht (Sep 11 2024 at 19:38):I just don't understand why it would be desirable to use
expectfor this instead of e.g.crash
crash. It is more noisy.expects in libraries to crash without needing to rewrite all of the libraries to use crash. Richard Feldman (Sep 11 2024 at 19:39):Brendan Hansknecht said:
You may also want
expects in libraries to crash without needing to rewrite all of the libraries to usecrash.
I think this is a disaster though :sweat_smile:
Brendan Hansknecht (Sep 11 2024 at 19:39):If this is an opt in feature that individual application authors decide to use or not, I don't see the cost.
Brendan Hansknecht (Sep 11 2024 at 19:40):What is the disadvantage
Brendan Hansknecht (Sep 11 2024 at 19:40):To just allowing it to be a flag?
Richard Feldman (Sep 11 2024 at 19:40):the cost is:
expect as intended, to help themselves debug stuff without regard to performanceexpects in this library are slow, and are slowing down my production application Richard Feldman (Sep 11 2024 at 19:41):Brendan Hansknecht said:
I just don't understand why it would be desirable to use
expectfor this instead of e.g.crash
- A lot less convenient to write the code with
crash. It is more noisy.
this is fair, but I think the answer to this would be to make an actual assert or something that's syntax sugar for crash
Richard Feldman (Sep 11 2024 at 19:42):like if that's something we want, I think it should be separate from expect and always work in prod, whereas expect never does, so the expectations and incentives are clear
Richard Feldman (Sep 11 2024 at 19:42):similar to assert! and debug_assert! in Rust
Brendan Hansknecht (Sep 11 2024 at 19:42):sure, but rust still has -C dbg-assertions for a reason
Richard Feldman (Sep 11 2024 at 19:43):I think that's a design mistake :sweat_smile:
Richard Feldman (Sep 11 2024 at 19:44):I just don't understand why you wouldn't write assert! in Rust if you want that behavior
Brendan Hansknecht (Sep 11 2024 at 19:45):I complain to the library author and now they are pressured to not use the feature the way it's originally intended
I would be surprised if this is a problem in practice. If you are turning expects on, you expect the code to slow down. The whole point is to trade off speed for more guarantees around correctness
Richard Feldman (Sep 11 2024 at 19:46):I understand the goal, I just think if you want a configurable thing like that it should be a separate language feature that's designed for that
Richard Feldman (Sep 11 2024 at 19:46):also, current expect (because of what it's designed for) doesn't halt the application like crash does, so it has no impact on correctness
Richard Feldman (Sep 11 2024 at 19:47):it just informs you if it failed, also by design
Brendan Hansknecht (Sep 11 2024 at 19:47):A really simple example: Roc compiler.
It is not nearly as fast in debug bulids. It catches a lot of errors with debug_assert!. We do not want the debug_assert! in the released version of the compiler. For testing purposes, it is super useful to make an optimized build with debug assertions. This runs fast and is able to give better error messages.
Brendan Hansknecht (Sep 11 2024 at 19:48):I use the equivalent config all the time at work.
Brendan Hansknecht (Sep 11 2024 at 19:48):But it is not a config we ever release to the public
Richard Feldman (Sep 11 2024 at 19:48):sure, and I think the "optimized build that's not for release" is a fine thing to support :thumbs_up:
Richard Feldman (Sep 11 2024 at 19:48):like keep them in optimized builds
Brendan Hansknecht (Sep 11 2024 at 19:48):doesn't halt the application like
crashdoes, so it has no impact on correctness
This is up to the platform. Or will be, just hasn't been implemented yet.
Richard Feldman (Sep 11 2024 at 19:49):I guess haha
Richard Feldman (Sep 11 2024 at 19:49):I mean it's not supposed to halt, but I guess a platform can be like "my implementation of logging expect to the console actually halts the program" and there's nothing the compiler can do to stop it, just like how its implementation of "allocate this memory" can also choose to halt if it wants to :laughing:
Brendan Hansknecht (Sep 11 2024 at 19:50):sure, and I think the "optimized build that's not for release" is a fine thing to support
I definitely don't get the distinction between this and an optimized build in rust with -C dbg-assertions
Richard Feldman (Sep 11 2024 at 19:50):it's the expectations
Richard Feldman (Sep 11 2024 at 19:50):like my expectation is "this code will never be run in production, so it's fine if it's slow, and the logged output doesn't have to be nice" etc.
Richard Feldman (Sep 11 2024 at 19:51):I want a feature where I can write expects with that in mind
Richard Feldman (Sep 11 2024 at 19:51):if we want a separate feature where I don't have that peace of mind, that's a reasonable thing to discuss!
Richard Feldman (Sep 11 2024 at 19:51):but I don't want to be like "hey what if we had this feature where the main selling point is peace of mind, but without the peace of mind?"
Brendan Hansknecht (Sep 11 2024 at 19:51):Like if we have:
--opitmized (optimized with expects on)--release (optimized with expects off)I would actually expect that would make leaving expects on more common than in rust where it is behind an obscure flag
Richard Feldman (Sep 11 2024 at 19:51):like as an analogy, imagine if there's a flag where now your tests affect production performance
Richard Feldman (Sep 11 2024 at 19:51):that is going to affect how you write your tests
Richard Feldman (Sep 11 2024 at 19:52):you can't just think of them as something that is decoupled, because they are now coupled
Brendan Hansknecht (Sep 11 2024 at 19:52):I do think you have a point around wanting a separate expect from assert akin to debug_assert and assert.
Richard Feldman (Sep 11 2024 at 19:52):you care about release builds, and you don't want release builds to be slow, so now you write fewer tests, spend more time performance-optimizing them and proofreading their output, etc. etc.
Brendan Hansknecht (Sep 11 2024 at 19:56):your tests affect production performance
I think what I still find off with this comment is that it is your choice. Like the tiger beetle folks opt into it cause they believe it leads to higher code quality and is worth the perf cost. Though I am sure they need to avoid expensive checks and are thinking about this. I bet almost all of the rest of the zig community never thinks about the perf cost here.
Richard Feldman (Sep 11 2024 at 19:56):I think writing high-quality production code requires thinking seriously about performance, and writing high-quality checks for correctness requires the freedom to not worry about performance
Richard Feldman (Sep 11 2024 at 19:57):mixing the two will inevitably lead to some combination of prod running slower and (some of) the checks being less effective than they could be if they were decoupled
Richard Feldman (Sep 11 2024 at 19:58):and I think it's totally fine if there's a separate feature for "this is like expect except it halts the program and is explicitly configurable as to whether it runs in prod"
Brendan Hansknecht (Sep 11 2024 at 19:58):I agree. I think my disagreement here is that I think the user should make this decision/tradeoff discussion.
Brendan Hansknecht (Sep 11 2024 at 19:58):both for expect and the theoretical assert
Richard Feldman (Sep 11 2024 at 19:59):because that way, people who are writing it know that:
crash must be used Sam Mohr (Sep 11 2024 at 20:04):Between this discussion and the implication that crash should never exist in a library, maybe we could introduce some compiler errors around using dangerous tools in anything but platforms and apps, meaning we ban crash and expect-crash in packages?
This leads to issues if a user has multiple of their own packages for code organization, but would probably help with this "I only trust myself to make these decisions, and no-one else" sentiment.
Richard Feldman (Sep 11 2024 at 20:07):well a crash and an assertion like this are equivalent in terms of when they should come up
Brendan Hansknecht (Sep 11 2024 at 20:08):crash is a hard one. Definitely still needed for the equivalent to unreachable! in rust. So I would expect to depend on libraries that use it (at least a little).
Richard Feldman (Sep 11 2024 at 20:08):they have the same end user experience of "the program exited ungracefully and might have vomited a stack trace in your face" so in general both should be reserved for "this should never happen, but we can't completely rule out that it could theoretically happen; if it does, exiting ungracefully is less bad than continuing"
Sam Mohr (Sep 11 2024 at 20:21):Brendan Hansknecht said:
crashis a hard one. Definitely still needed for the equivalent tounreachable!in rust. So I would expect to depend on libraries that use it (at least a little).
It may actually be viable to have the user need to pass the crash keyword in when it would be used. It's less ergonomic, but then even if a crash happens, it has to be opted into by the app author. An example would be
cliParser =
{ Cli.weave <-
file: Param.str { name: "file" },
verbosity: Opt.count { short: "v", long: "verbose" },
}
|> Cli.finish { name: "transformer" }
|> Cli.assertValidOr crash
Where the type of assertValidOr is
assertValidOr : Result CliParser err, (Str -> CliParser) -> CliParser
Then you can always grep for expect and crash, knowing they'll only be in your own repo
Brendan Hansknecht (Sep 11 2024 at 20:28):You could, but I don't think it would be worth it. Like for example, Dict uses crash.
Brendan Hansknecht (Sep 11 2024 at 20:28):So anything that uses a Dict would require crash be passed in.
Brendan Hansknecht (Sep 11 2024 at 20:29):I think many data structures will use crash somewhere
Sam Mohr (Sep 11 2024 at 20:29):Well, the standard library should be fine
Sam Mohr (Sep 11 2024 at 20:30):If we make crash available for packages, there are definitely places where code will be more readable and also more performant with the inline usage of crash
Sam Mohr (Sep 11 2024 at 20:30):So there are obviously benefits
Brendan Hansknecht (Sep 11 2024 at 20:32):Sam Mohr said:
Well, the standard library should be fine
I think we should treat other data structure libraries the same as the standard library for the most part. Dict could be a regular package instead of part of the stand library. I'm sure there will be other forms of dictionaries that users will want. As such, they will want crash so that they can have an equivalently nice API to the standard library.
Sam Mohr (Sep 11 2024 at 20:34):I guess I don't know how much of an issue unreachable! is in other languages like Rust. It's definitely fine in popular libs that are well tested, but I don't know if it means we need to do that
Sam Mohr (Sep 11 2024 at 20:37):Brendan Hansknecht said:
Sam Mohr said:
Well, the standard library should be fine
I think we should treat other data structure libraries the same as the standard library for the most part. Dict could be a regular package instead of part of the stand library. I'm sure there will be other forms of dictionaries that users will want. As such, they will want
crashso that they can have an equivalently nice API to the standard library.
I think you get just as nice of an API, with one caveat: you need to now provide a crash module param. It now makes it obvious that we use crash, but usage is otherwise fine.
Sam Mohr (Sep 11 2024 at 20:39):I'll make clear that I agree that this makes it more awkward to write libraries, I'm just trying to see if there's a way to allow app authors to not worry about unexpected crashes (besides div by zero errors)
Sam Mohr (Sep 11 2024 at 20:42):I would also follow up with "this could extend to expect", but it seems like we expect them to work differently and be used in different contexts, so maybe not wanted for expect
Richard Feldman (Sep 11 2024 at 20:42):importantly, all Roc programs can crash (regardless of whether crash exists) no matter what - e.g.
myCrash : {} -> *
myCrash = \{} ->
causeStackOverflow = \num ->
if 1 + causeStackOverflow num == 0 then
causeStackOverflow num
else
causeStackOverflow num
causeStackOverflow 0
there's actually a tutorial section on why crash is in the language
Screenshot-2024-09-11-at-4.43.41PM.png
Sam Mohr (Sep 11 2024 at 20:45):You're making me throw up imagining this code in someone's library as a workaround haha
Richard Feldman (Sep 11 2024 at 20:46):one of the main reasons for adding crash was that a question that came up multiple times in Zulip in the early days was "what do I do if there's a conditional branch that I think should never come up, but technically might, and there's no reasonable value I could return there?" and this workaround was the only answer :big_smile:
Sam Mohr (Sep 11 2024 at 20:48):a.k.a. unreachable!
Sam Mohr (Sep 11 2024 at 20:48):Okay, then as expected, we're not gonna solve this expect problem by lumping it in with crash, they're different problems, and crash should still be a thing
Brendan Hansknecht (Sep 11 2024 at 20:55):Sam Mohr said:
You're making me throw up imagining this code in someone's library as a workaround haha
I am guilty of writing that many times in the early days
Sam Mohr (Sep 11 2024 at 20:57):Well, with no crash keyword... You were wrongfully imprisoned
Sam Mohr (Sep 11 2024 at 20:57):Andy DuFresne
Brendan Hansknecht (Sep 11 2024 at 21:12):oh, though I wouldn't cause a stack overflow, I would cause an integer overflow/underflow based crash
Like 255u8 + 1
Sam Mohr (Sep 11 2024 at 21:14):That example would probably resolve the int type to U8, so in this case probably an overflow, but it depends on the int type
Sam Mohr (Sep 11 2024 at 21:14):No, actually I think it would do U64?
Brendan Hansknecht (Sep 11 2024 at 21:15):I specified U8, so the 1 will also be a U8.
Brendan Hansknecht (Sep 11 2024 at 21:15):And it will overflow the U8
Brendan Hansknecht (Sep 11 2024 at 21:15):We don't promote implicitly
Sam Mohr (Sep 11 2024 at 21:16):I'll have to re-read https://github.com/roc-lang/roc/blob/3d9c4673af25349be43e0e8e703a0f4b36176577/crates/compiler/constrain/src/builtins.rs#L16
Sam Mohr (Sep 11 2024 at 21:16):I was referring to Richard's example, definitely U8 in yours
Brendan Hansknecht (Sep 11 2024 at 21:18):richard's would be I64. In a debug build, it would stack overflow. In an optimized build, I think it would run forever.
Matthieu Pizenberg (Sep 13 2024 at 16:47):You're making me throw up imagining this code in someone's library as a workaround haha
I’ve written that kind of black hole a few times for elm libraries ... guilty
Agus Zubiaga (Sep 13 2024 at 22:59):I’ve done that in Elm once or twice when I have a “safe unsafe” thing that I statically verified is ok (via elm-review or tests), but the language doesn’t know it.
Richard Feldman (Sep 13 2024 at 23:01):yeah this illustrates the pro and con of crash compared to not having it (which is why we didn't, at first)
Richard Feldman (Sep 13 2024 at 23:02):if you don't have it, the hack workarounds is so terrible that it's obvious you should only use it when there is no reasonable alternative whatsoever
Richard Feldman (Sep 13 2024 at 23:02):but when it's a feature, it's easier to reach for and questions come up about when it should or shouldn't be used :big_smile:
Richard Feldman (Sep 13 2024 at 23:03):idea: rename it to crashBecauseThisShouldBeUnreachable
Sam Mohr (Sep 13 2024 at 23:05):A lot of naming jokes in programming spaces. It's almost like we all share the same trauma
Aurélien Geron (Sep 14 2024 at 00:39):Perhaps crash Unreachable, crash Todo and maybe a few more "legit" reasons to crash, and everything else is forbidden or floods you with warnings?
Kasper Møller Andersen (Sep 14 2024 at 08:28):Lately I've been thinking a lot about error handling, and as it pertains to assertions in production, this is how I view it:
There are two types of errors: expected errors and unexpected errors. Expected errors are things like some service being down, so your HTTP call fails, and unexpected errors is when your chess pawn manages to be alive in the game, but with a position outside the board.
I've got thoughts on dealing with expected errors, but I'll focus on the unexpected errors here. Usually they come in two flavors:
Neither of these two states is something you want to expose in the signature of your API necessarily. Both because they should in fact not be able to happen, but also because the users can't really do anything about them.
The thing that should definitely happen in both cases, is that the user should be given clear instructions on how to report that this happened. I really want to know that my code ran into this kind of issue, so it should be clearly reported. This is one of my main gripes with error handling in Elm.
If I want to log that I hit such an "impossible" case, I need to return a Cmd from my function. But the caller can't tell what's going on. It just looks really suspicious that my movePawn function returns a (Board, Cmd) tuple. What is that command for?! Or worse, I can't even report this if I run upon it in my view function, because the signature forbids me from returning a command. But view is basically the function where I combine all of my state into one thing, so it's a natural place to discover that I have painted myself into a corner. So more often than not, the error ends up being swallowed, and I never knew it happened.
An essential component of reporting an unexpected error like this is: context, context, context. And as much as I like functional error handling, it doesn't have a good story around giving context for errors. My kingdom for a stack trace! And I say that, knowing full well that stack traces are extremely limited in what they can say, but at least they're _something_.
Ideally, I would be able to (in a production environment) get information like:
This is a big ask of course, but to me it sounds like exactly what assertions in production are trying to fix. I wouldn't necessarily expect such assertions to crash in production, but I want to be notified when they fail. They provide context for how things ended up where they did.
Kasper Møller Andersen (Sep 14 2024 at 08:38):The mantra of "more context" is also useful for expected errors I think, though it's something the developer can better control in there. However, when I run upon some expected error in production, my first regret is usually that I didn't capture more context for the error. So having the assertions (or some better tool) there is also useful.
Richard Feldman (Sep 14 2024 at 11:29):I think there's actually a potentially straightforward way for platforms to expose a "log including stack trace" effect today, and there's a way we can preserve that in the discussions about effect systems
Richard Feldman (Sep 14 2024 at 11:30):today (where we don't have the effect interpreter state machine yet) platforms can already produce stack traces on any effectful operation, because there's a normal stack - I think currently they only do it for crash in practice, but there's nothing stopping any platform today from doing it for any operation
Richard Feldman (Sep 14 2024 at 11:30):which means they could include a new log primitive which provides the stack trace so that it can be sent off to a logging service
Richard Feldman (Sep 14 2024 at 11:32):(there's a separate question of whether "I have a pure function that could error out normally - e.g. in a non-crash way - and I really want a stack trace for that and don't want to wait for the nearest effect boundary to be able to log one, but I consider that a separate "should the language support a logging primitive that is side-effecting but isn't considered a side effect" discussion)
Richard Feldman (Sep 14 2024 at 11:34):so as long as we preserve the ability of platforms to declare both synchronous (e.g. for a hypothetical Time.now operation) and async (effect interpreter state machine) effects, there's a path for platforms to offer "async stack traces"
Richard Feldman (Sep 14 2024 at 11:35):but we'd need to figure out how to do the async state machine in a way where platforms still (somehow) have access to the stack of function calls that led to a particular state being presented in the state machine
Richard Feldman (Sep 14 2024 at 11:35):(this is a problem any async runtime needs to figure out if they want to offer "async stack traces" - which I think would be great to offer in Roc)
Richard Feldman (Sep 14 2024 at 13:11):for example, a way we could do that is to let platforms specify "this is a sync effect" (like today, in which case the host can get the stack trace without any compiler intervention) and then also "this is an async effect" along with a flag for including call stack information between where the continuation started and when the async effect wants to run
Richard Feldman (Sep 14 2024 at 13:12):so host authors would need to record that stack info between state transitions, and then when you run an effect that asks for it, they'll have that in memory and can provide it
Richard Feldman (Sep 14 2024 at 14:47):Kasper Møller Andersen said:
And as much as I like functional error handling, it doesn't have a good story around giving context for errors. My kingdom for a stack trace! And I say that, knowing full well that stack traces are extremely limited in what they can say, but at least they're _something_.
Ideally, I would be able to (in a production environment) get information like:
- what line of code produced this error
- how did my code end up in that function
This is a big ask of course, but to me it sounds like exactly what assertions in production are trying to fix. I wouldn't necessarily expect such assertions to crash in production, but I want to be notified when they fail. They provide context for how things ended up where they did.
of note, although it's very common for languages to couple stack traces to exceptions, there's no innate relationship between them
Richard Feldman (Sep 14 2024 at 14:50):like on a technical level, a backtrace of the current call stack can be obtained anytime
Richard Feldman (Sep 14 2024 at 14:51):and then if you want to preserve that across async, that's a separate consideration but also not coupled to halting execution
Richard Feldman (Sep 14 2024 at 14:57):that said, a good reason to not expose "hey just give me the current stack trace" as a builtin or language primitive is that (1) that operation isn't pure (it gives a different answer depending on how the function was called, even if its arguments are the same), and (2) it means if you call third party packages, they can now access a stack trace which exposes some of your source code info to them and there's no way for you to prevent this or even know it's happening
Richard Feldman (Sep 14 2024 at 14:58):both of which are why I think facilitating a way for platforms to expose effectful logging operations that include (async) stack traces seems like the best way to achieve the goal of stack trace context ending up in logs without any purity or security problems
Richard Feldman (Sep 14 2024 at 15:01):and then since it doesn't require halting, you can immediately log the trace right when the problem happens, and then return Err to let it continue propagating as normal
Brendan Hansknecht (Sep 14 2024 at 15:05):Like with the split between expect and assert. I think there is a separate split between dbg and log that we should consider
Brendan Hansknecht (Sep 14 2024 at 15:06):I think a log primitive that is not considered an effect would be deeply useful for these kinds of situations.
Richard Feldman (Sep 14 2024 at 15:07):I think it's worth considering but I definitely think it's worth trying without first
Brendan Hansknecht (Sep 14 2024 at 15:07):Yep. Really need to see large software in roc before we can usefully evaluate this
Richard Feldman (Sep 14 2024 at 15:09):unlike dbg and inline expect, the downside of "logging in pure functions is allowed and not considered pure even though it's a side effect" has more serious implications bc we can justify optimizing away a dbg or expect, but "this log message got skipped because the optimizer decided we didn't need to run the pure function again" is a bigger deal
Brendan Hansknecht (Sep 14 2024 at 15:19):While I agree with the theoretical distinction, we don't optimize away dbg in practice and if we did, it would make debugging really annoying.
Brendan Hansknecht (Sep 14 2024 at 15:19):A platform today could use dbg as a generic log if it wanted.
Brendan Hansknecht (Sep 14 2024 at 15:20):The only reason debugs get removed today is due to old limitations.
Kasper Møller Andersen (Sep 14 2024 at 15:31):How much does the final stack today resemble the stack as a developer envisions it when reading the code, even for sync code? I mean, will there be so much inlining and reordering that just looking at a straight call stack would be more confusing than helpful?
Brendan Hansknecht (Sep 14 2024 at 15:35):Even today our stack traces are pretty hard to follow and I wouldn't expect that to get better.
Or well, eventually well generate good debug info. So if you can pay the cost of reading debug info, it should get better, but raw stack traces in roc will probably always be very bad. Lots of small lambdas with no names are terrible for system stack traces.
Brendan Hansknecht (Sep 14 2024 at 16:15):Oh, one extra clarification, the reason the stack trace is bad is actually due to retaining too little information.
Often tons of functions will get inlined (cause tons are single use lambdas or short in general). On top of that, it is pretty common for the names of the functions that are kept to be terrible. So it becomes a very painful problem to map that back to anywhere specific in the code.
Brendan Hansknecht (Sep 14 2024 at 16:16):The worst is when something anonymous is kept (which is common in roc due to heavy lambda use). You get a module name and a number in that case.
Joshua Warner (Sep 14 2024 at 16:53):For what it's worth at work, we deploy a rust service where we have assertion sprinkled around liberally. This has been really critical in catching a variety of non-trivial data model bugs. We also have a very small number of expensive debug assertions that are stripped out in our production builds, but these are very much the exception and not the rule.
Joshua Warner (Sep 14 2024 at 16:55):In my experience, assertion performance almost never matters in practice, but when it does matter, it matters a lot.
Richard Feldman (Sep 14 2024 at 17:02):yeah and I think it also matters what you're building
Richard Feldman (Sep 14 2024 at 17:03):like a game might want lots of debug assertions and zero that actually crash the game if they fail
Kasper Møller Andersen (Sep 14 2024 at 18:00):Brendan Hansknecht sagde:
Oh, one extra clarification, the reason the stack trace is bad is actually due to retaining too little information.
Yeah, that's what I was imagining. Even assuming DWARF debug info can make up the difference, I was wondering if maybe there was a better approach waiting to be discovered, which better aligns with the mental model for Roc.
For example, assuming the compiler may choose to reorder, inline, and skip pure functions (even with logging), maybe the existing notion of logging is too big a mismatch for Roc? What if Roc instead had something analoguos called, let's say, "tracking". It looks a lot like logging when you write your code (e.g. you can call track.info with some message), but it is essentially an effect the compiler is allowed to memoize. So if a function a is pure except for a track.info call, the compiler may choose to skip calling a multiple times, but only if it makes sure to call track.info with the original message again (with some additional marker that this is a repeat of an old message).
I don't know if that's a good idea in practice, but I like that this is still pretty close to being logging, but still different. This may then be enough to remove people's expectations of how the logging is supposed to work, and teach them how it works in Roc.
Maybe the idea of a call stack is similarly too big of a mismatch for Roc? Maybe you need a proper call graph? And so on and so forth with other debug tools.
Richard Feldman (Sep 14 2024 at 18:30):I think there are things we can do to make stack traces more useful, especially if we're doing our own inlining
Matthieu Pizenberg (Sep 15 2024 at 09:25):BTW, having worked on many code bases that are simply not usable without compiling in release mode in rust, I also would like the ability to have some kind of logs/debugs/asserts available with optimized compilation. For things that handle lots of data, like images/video processing or math optimization with big matrices in general, it is critical to have optimized build. Otherwise they are simply unusable.
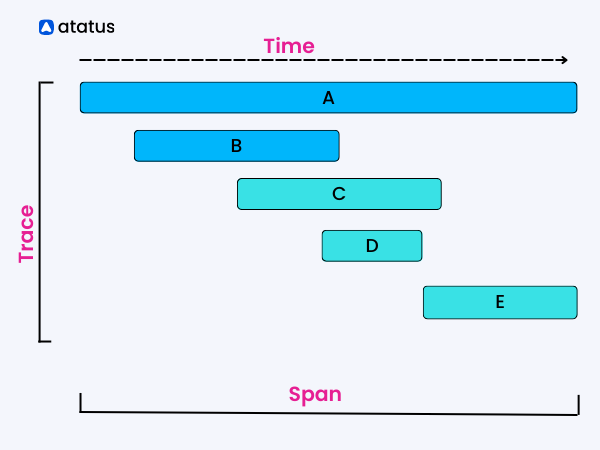
Jasper Woudenberg (Sep 15 2024 at 09:26):This is a bit of a tangent, but I would love if Roc had great support for tracing, either directly or by making it very easy for platforms to include it. If you're unfamiliar, traces capture what your program is doing in a tree format that looks a bit like this:
https://www.atatus.com/blog/content/images/2023/06/span-distributed-tracing.png
My experience is with web-servers and I don't know how well this generalizes to other domains. Within web servers though, going from debugging production environments using log output to using tracing output has been night and day. But in the places where I introduced traces for debugging production it took some effort to set up. If Roc (platforms) made that work by default out of the box, I think it could blow a lot of people's minds.
Tracing data has strictly more structure than logging data, so it's possible to turn traces into logs but not vice-versa. If Roc had good support for tracing we might not need separate logging primitives.
To have great tracing in a web server I think it's important that all the effects "at the edges of the application" are traced, i.e. outgoing SQL queries, outgoing HTTP requests, incoming HTTP requests, file reads, etc. Roc platforms are very well set up to deliver that. If the user is then able to add some of their own traces around effectful computations with relevance in the application domain, then I think we'd already be in a very good place. Being able to trace sync code I think is less important, because if you've got visibility into what data effectful functions are receiving and returning it's relatively straight-forward to work out the behavior of the remaining, pure code.
How this relates to exceptions and stack traces: The spans that make up a trace form their own 'stack of contexts', we might use it for stack traces. Because this trace context is designed for debugging by the platform and application author together in my experience they have much better signal/noise ratio than classical stack traces. They are less detailed than a full stack trace because it doens't contain every function call, but I think that's much less important in a functional language where effects aren't lurking everywhere.
Isaac Van Doren (Sep 15 2024 at 13:41):I completely agree. It would be good to spend some time thinking about how Roc can support
observability features like distributed tracing. At work we use Java and heavily integrate with Datadog and it is amazing. There is such rich information. Tracing, profiling, and we can even instrument particular pieces of code at runtime. It will really help the production adoption story if it is easy to setup observability for Roc.
Kasper Møller Andersen (Sep 15 2024 at 16:26):I haven't used tracing myself, but my understanding is that tracing and logging are complementary. I imagine the best combination allows log messages to be associated with some trace. Or is that not your experience?
Jasper Woudenberg (Sep 15 2024 at 17:33):Some folks promote this concept of there being "three pillars of observability": logging, tracing, and metrics. I'm personally not a fan of this idea and you see more and more push-back in blogs and talks on this idea.
I like to think of a log message as a special case of a span (one of the boxes in a trace, see picture above). If you take a span, don't give it a parent, don't let it wrap any code (i.e. give it a duration of 0) and set a single string as its only metadat, then you've got a log message. So in this view being able to trace means you've already got the ability to log by using the tracing API in a restricted fashion.
Jasper Woudenberg (Sep 15 2024 at 17:43):In more practical terms, where I might have previously written a logging line like this:
Log.info "Starting work on job #{job_name} (#{job_id})"
Now that I'm more comfortable with tracing I would instead write something like this:
Observability.span "run job" { job_name, job_id} \{} -> run_job "some_arg" 42
(given a hypothetical Roc logging and tracing api)
I find that a lot of the log messages I used to write were marking the start/end of some operation and creating spans is a better fit for that given you get things like measuring the duration of those operations for free.
Kasper Møller Andersen (Sep 15 2024 at 19:01):Viewing tracing as a super set of logging seems reasonable to me too. Aside from marking entry and exit points, the main kinds of logs I write are also just "program was here", so I can see branches taken and that kind of thing. And having those tied to a span is nice anyway, in many cases at least.
I think the advantage of logs may be that they are easier to get started with and understand, whereas tracing probably requires more tooling to make the most of. That is, reading raw tracing info in stdout seems like a pain compared to just reading logs. But if the tracing framework can produce such logs anyway, then I'm happy to let it all be tracing.
I also don't know well the concept of a span maps to, say, a game. I think I would expect game events to map cleaner to raw logs at least.
Isaac Van Doren (Sep 15 2024 at 19:47):That’s interesting! At work we mostly use the tracing that is automatically captured by the Datadog SDK, but maybe we would benefit from creating more specific spans. Right now for us logging definitely serves a separate purpose from tracing.
Jasper Woudenberg (Sep 15 2024 at 21:09):It's possible to flatten traces to linear log output. For instance, if there's a span with some name do a thing, we might turn that into log output by printing a line [start] do a thing when the span starts and a line [stop] do a thing where it ends.
In a couple of places where I worked we had a single API for instrumenting code with traces, and then used the tracing data collected to separately:
Last updated: Jul 23 2026 at 13:15 UTC